(通讯员:唐厂)2017年7月,国务院印发的《新一代人工智能发展规划》中指出,人工智能发展已经进入了新阶段,成为国际竞争的新焦点和经济发展的新引擎。发展机器学习方法,挖掘数据有用价值已经上升为国家的重大战略需求。计算机学院人工智能系老师们面向国家重大战略需求,长期致力于机器学习和数据挖掘方面的研究,以加速人工智能技术的落地应用,在深度迁移学习、非凸优化机器学习、无监督/半监督/自监督学习等方向做出了一系列落地于实际应用的研究成果。
一、代价敏感深度迁移学习助力机器学习与数据挖掘技术落地应用
印制电路板外观缺陷检测是印制电路板行业非常重要的环节,直接影响了该行业的生产效益和自动化程度。现有的外观缺陷检测方法一般采用外观检查机来协助完成,外观检查机的利用实现了一定程度的生产自动化,在一定程度上减轻了工人的工作量,但仍然还存在人工确认缺陷效率低下、高贵费时等很多问题。蒋良孝教授团队针对性提出了基于代价敏感深度迁移学习的印制电路板外观缺陷检测新方法,提高缺陷检测的精度和效率,从而提高印制电路板行业的生产效益和自动化程度。研发的电路板外观缺陷检测系统可以在普通PC机上部署实现,具有广阔的市场应用前景。系统的示范应用可以带动相关产业,预计可节约人力资源40%以上,对提高我国电路板行业的生产效益和自动化程度、推动人工智能技术落地应用都具有十分重要的意义。
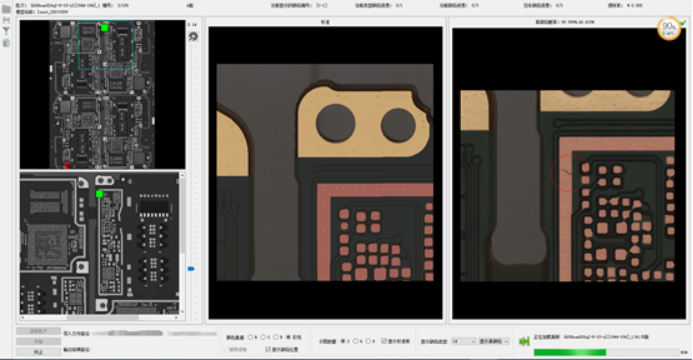
图1印制电路板外观缺陷检测系统运行界面
二、非凸优化机器学习问题求解与高性能实现
在高性能计算环境下研究机器学习问题优化、实现及其地学应用,融合优化方法+高性能编程求解。具体地,我们针对机器学习中各种非凸优化面临的收敛波动、效率瓶颈、鞍点陷入等问题,(1)设计非凸优化问题的并行分布式剖分策略,研究非凸问题的凸化理论与方法,研究非凸函数直接优化的理论与技术;(2)设计满足多代价约束的超算计算模式,映射至多主协处理器异构、众核、多核高性能架构的并行编程模型实现。我们还对将上述研究应用于高维、稀疏、多源、异构、不完备地学数据以及其他民用工业数据及其衍生的相关科学问题感兴趣。
近年来,张锋老师课题组聚焦于矩阵分解、张量分解机器学习非凸优化问题,在以正则化因子为核心的目标函数替换凸松弛技术、矩阵二维块分布式计算的负载均衡问题、分布式计算数据通信的量化压缩策略,以及他们的“中央处理器+协处理器”的混合异构超算平台实现等方面取得了成果并与区块链等技术结合,与企业和研究所合作,开发区块链加密钱包芯片、气体传感器阵列,嵌入于智能水务、智能天然气的监测、管控、预警和响应系统,系统已在香港地区进行部署,得到初步应用。
图2矩阵分解负载均衡策略
图3加密钱包芯片功能示意图
三、无监督/半监督智能计算方法挖掘海量数据核心价值
随着人工智能与大数据时代的到来,海量的数据应运而生,而数据的真实标签获取是一个非常耗费人力和财力的过程。因此,如何从海量无标签或者少量标签的数据中挖掘有用信息是人工智能技术落地应用必须克服的一大问题。
实际问题中,我们遇到的海量数据如文本、语音、图像、视频、基因微阵列等大多分布在高维的特征空间中。一方面,这些高维特征不可避免地增加了学习模型的计算复杂度;另一方面,这些高维特征常常混有大量的噪声和冗余特征维度,会严重影响学习模型的性能。这两方面给数据的特征表示带来了巨大挑战。唐厂教授课题组长期致力于海量无监督高维数据的降维以及聚类分析方面的工作,并在这一领域取得了一系列原创性成果。
针对数据的高维问题,唐厂教授课题组提出了不依赖于任务的特征选择和特征提取算法,首次从理论上揭示了特征选择和特征提取的关系,将两者整合到一个统一的框架中。在保持原始数据局部几何流形结构和关联关系的原则下,将数据从原始高维特征空间映射到简洁的低维特征空间中,显著提升了后端分类/聚类模型的精度。为了克服原始数据局部几何流形结构约束过程中范数引导的图拉普拉斯正则对噪声数据的敏感性,首次提出了范数引导的图拉普拉斯正则并给出了其可收敛的理论优化求解方法,显著提升了特征选择模型的鲁棒性。考虑到在许多现实场景中,带标记的样本往往很难获取,为了充分利用有限的带标记样本,利用自适应超图约束准则,提出了高阶关系嵌入的半监督特征提取算法。引入自适应超图学习模型挖掘大量无标记样本和少量带标记样本之间的高阶关联关系,进而充分利用无标记样本的信息服务于学习模型,从而显著提升了分类精度。以上两项研究成果已经分别成功地应用于浙江铭道通信技术有限公司的语音大数据分析平台以及多媒体调度系统,分别解决了语音大数据的高维、高噪声和高冗余的问题以及多媒体数据的表现多样化和分布散乱的问题,为铭道通信技术有限公司的BI智能语音大数据分析平台和多媒体调度系统节约了上千万的运行成本。
图4 BI智能语音大数据分析平台
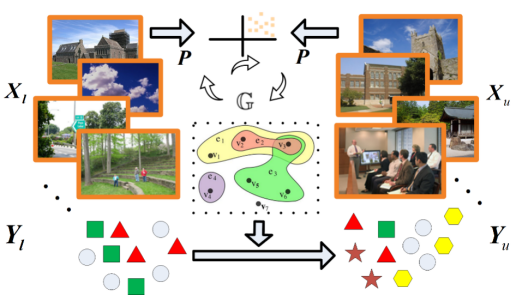
图5自适应超图约束的半监督特征提取算法框架图
对样本进行多源、多样化精确感知,并充分利用不同视图下的特征构建下游数据挖掘/机器学习模型是非常有必要的。然而,在大数据时代,对数据样本进行不同视图描述的特征之间存在互补信息和一致信息的同时也不可避免地引入了冗余信息。如何挖掘数据多样化特征的互补性和一致性并尽量减少冗余信息的干扰是构建高效数据挖掘/机器学习模型面临的严峻挑战。基于数据的自表征模型,唐厂教授课题组创新性地提出了多样性和一致性协同约束的多视图聚类算法,从而有效地利用了两者之间的耦合作用学习原始数据的相似度关系,有效提升了数据聚类的精度。该项研究成果已经成功地应用于西安因诺航空科技有限公司的无人机集群协同系统中,有效地提升了无人机集群编队对抗的智能化水平,降低了人工标注成本,使操作人员的工作量降低了30%。
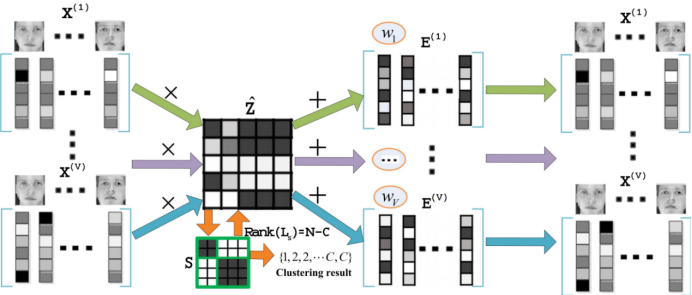
图6多样性和一致性协同约束的多视图聚类算法
四、自监督机器学习算法助力视频情感计算与应用
基于视频信息的情感计算已经成为人工智能和计算机视觉领域近年来一个备受关注的研究方向。2018年中国科协发布的12个领域60个重大科学问题中指出,人与机器的视频情感交互是现代人工智能技术急需突破的关键技术之一。
针对非约束视频情感计算中的两大难点问题,一是视频中存在大量冗余的情感无关的帧;二是视频中的人脸情感变化相对于其他的运动信息是非常微弱的。现有的机器学习方法难以精确定位和模拟非约束视频中情感相关序列帧及其情感变化。针对这些问题,刘袁缘老师课题组提出了基于自监督Transformer的视频情感强度表征算法,可以精确的定位情感运动发生的位置的同时,快速建模情感变化。主要过程包括如下两个步骤:(1)情感片段解构和表征,首先将视频抽样划分为等长的多个片段,然后对每个片段通过所提出的级联自注意力及Transfomer进行片段内和片段外的情感信息建模,得到有效的情感片段表征;(2)情感时序自监督重构,为了学习视频中情感的敏感时序变化,将视频片段的顺序在学习之前进行打乱,然后通过重构预测的自监督学习方式,强迫模型学习其时序敏感的关系,从而获得鲁棒的情感识别。
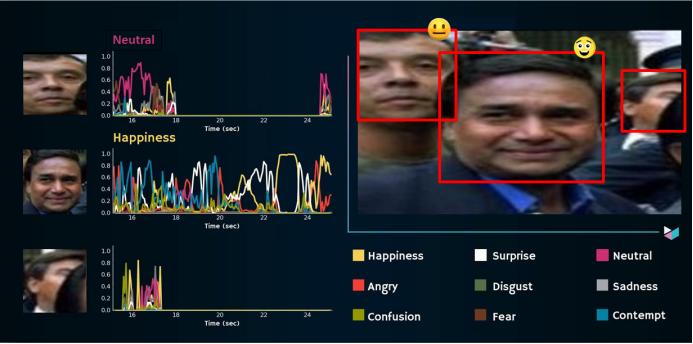
图7 非约束情感计算及应用
后记:全球已经进入了人工智能的新时代,许多发达国家已经相继发布了“人工智能研究与发展”的战略规划。人工智能也成为国际上国家之间新的竞争热点。虽然目前有很多人工智能技术已经趋于成熟,但是仍有许多开放未解决的难题,需要相关的从业人员去探索。我们将顺应国家的发展战略,继续利用自身优势和条件,为国家在人工智能领域贡献自己的一份力量,培养国家所需要的高科技创新性人才!



